
Teil 1: WDF * IDF Analysen – der neue Trend in der Suchmaschinenoptimierung
 In der SEO-Branche und somit auch unter unseren Kunden wird derzeit eine Thema heiß diskutiert: Die WDF*IDF Analyse. Ein altes Thema aus dem Information Retrieval der 70er Jahren wurde von Karl Kratz hervorgeholt und hat viele SEOs aus ihren Liegestühlen in der Südsee aufgescheucht. „Die Keyworddichte ist out, WDF*IDF ist in“ lautet plötzlich die Botschaft in der SEO-Szene. Bei vielen Kunden ist die Verwirrung groß: das bisschen Prozentrechnung für die Keyworddichten bekommen die meisten ja noch hin. Wenn jetzt noch Logarithmen dazu kommen, ist die Verzweiflung vielfach groß. Das merken wir dann an Anfragen von aufgescheuchten (Neu-)Kunden die uns teileweise völlig unreflektiert fragen: „Schreibt Ihr auch dieses WDF*IDF Texte? Da brauche ich 200 Stück von“.
In der SEO-Branche und somit auch unter unseren Kunden wird derzeit eine Thema heiß diskutiert: Die WDF*IDF Analyse. Ein altes Thema aus dem Information Retrieval der 70er Jahren wurde von Karl Kratz hervorgeholt und hat viele SEOs aus ihren Liegestühlen in der Südsee aufgescheucht. „Die Keyworddichte ist out, WDF*IDF ist in“ lautet plötzlich die Botschaft in der SEO-Szene. Bei vielen Kunden ist die Verwirrung groß: das bisschen Prozentrechnung für die Keyworddichten bekommen die meisten ja noch hin. Wenn jetzt noch Logarithmen dazu kommen, ist die Verzweiflung vielfach groß. Das merken wir dann an Anfragen von aufgescheuchten (Neu-)Kunden die uns teileweise völlig unreflektiert fragen: „Schreibt Ihr auch dieses WDF*IDF Texte? Da brauche ich 200 Stück von“.
Grund genug also, die Thematik einmal ausführlicher zu erläutern. In einer dreiteiligen Reihe stellen wir die Konzepte, die hinter einer WDF*IDF Analyse stehen vor und geben sowohl Auftraggebern als auch Autoren Hinweise, wie sie mit diesem Werkzeug sinnvoll umgehen, und wann sie sich lieber auf andere Dinge verlassen sollten. Im ersten Teil wird es recht theoretisch. Hier werden die Hintergründe einer WDF*IDF Analyse Erläutert. Der zweite Teil unserer Reihe befasst sich dann mit der Auswertung der Analyse und dem Schritt zum Textauftrag. Der dritte Teil betrachtet die Problematik aus Autorensicht und gibt Ratschläge, wie Aufträge mit einem WDF*IDF Hintergrund angegangen werden sollten.
WDF * IDF – Eine Technik aus dem Information Retrieval der 70er Jahre
Die Gewichtungen von Termen nach einem WDF*IDF Verfahren findet sich zum ersten Mal im Vektor Space Modell Gerald Saltons SMART Information Retrieval System Anfang der 70er Jahre. Auf diesem Modell basieren auch heute noch die Kern-Funktionen der meisten Suchmaschinen.
Zentrale Idee des Vektor Space Modells ist, dass alle Dokumente durch Vektoren in einem n-dimensionalen Raum repräsentiert werden. Betrachtet werden dabei alle sinngebenden Terme der Dokumente, d.h. Stoppwörter werden nicht mit in die Analyse einbezogen. Diese Terme bilden die Basisvektoren des Vektorraums. Das skalare Vektorelement eines Dokumentvektors stellt dann das Gewicht dar, welches der betreffende Term in dem jeweiligen Dokument hat.
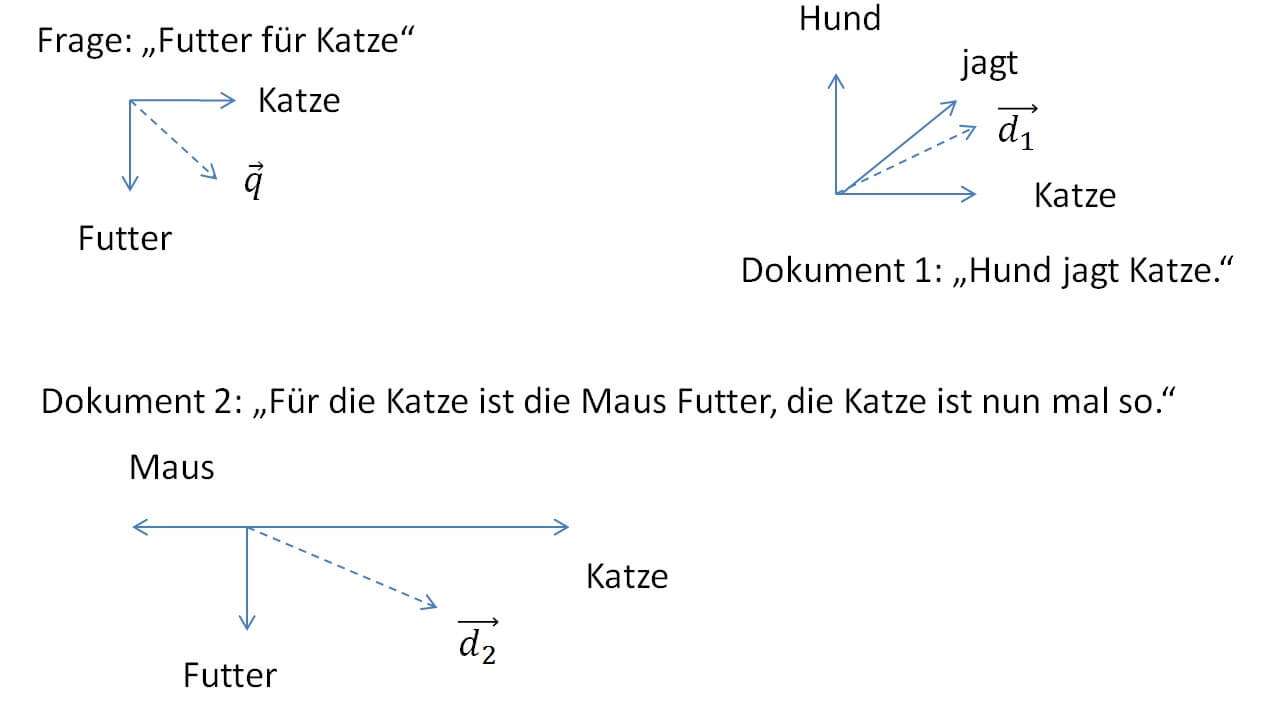
Betrachtet man nun nicht nur die Dokumente als Vektoren, sondern auch die Suchanfrage, dann findet man die Dokumente, die am besten zur Suchanfrage passen durch eine Vergleich der Dokument-Vektoren mit dem Vektor der Suchanfrage. Dokument-Vektoren, die in die gleiche oder eine möglichst ähnliche Richtung zeigen wie der Vektor der Suchanfrage, enthalten vermutlich die Antwort auf die gestellte Frage.
Ein ganz einfaches Beispiel: Zur Suchanfrage „Futter für Katze“ soll herausgefunden werden, welches Dokument die beste Antwort liefert. Zur Auswahl stehen die Dokumenttexte
d1: „Der Hund jagt die Katze“
d2: „Für die Katze ist die Maus Futter, die Katze ist nun mal so“.
Nach Entfernung der Stoppwörter bleiben folgende sinngebende Terme im System der Suchmaschine hängen:
- Katze
- Futter
- Hund
- Maus
- jagt
Die Richtungs-Ähnlichkeit von Vektoren ist mathematisch durch den Winkel zwischen den einzelnen Vektoren fassbar und somit berechenbar für die Algorithmen von Suchmaschinen.

Offensichtlich beantwortet das zweite Dokument die Suchanfrage am besten. Der Winkel zwischen dem Dokumentvektor und dem die Suchanfrage darstellenden Vektor q ist dabei deutlich kleiner als der Winkel zum ersten Dokument. In diesem Beispiel sind stark vereinfachend die Termgewichte als absolute Häufigkeiten der Terme eingesetzt worden. In der Praxis werden hier dann die WDF*IDF Werte (s.u.) verwendet.
Das Termgewicht ist wichtiger als die Keyworddichte
Um die Bedeutung eines Terms für ein Dokument zu bestimmen, werden zwei Faktoren errechnet und miteinander verknüpft. Beide Faktoren versuchen die Bedeutung eines Terms für ein Dokument aus verschiedenen Perspektiven zu bewerten.
WDF, die within document frequency
Mit dem WDF – Faktor wird die sogenannte within document frequency ausgedrückt. Sie gibt die Bedeutung eines Terms für ein Dokument an, basierend auf der Häufigkeit seines Auftretens bezogen auf die Anzahl aller Wörter, die in diesem Dokument verwendet wurde. Um Ausreißer im Wertebereich zu vermeiden, wird dieses Verhältnis bei der Berechnung durch eine Logarithmusfunktion und einige Korrekturwerte gedämpft.
IDF, die Inverse Document Frequency
Die inverse document frequency versucht die Bedeutung eines Terms bezogen auf alle Dokumente im Dokumentkorpus zu erfassen. Kommt ein Term in allen Dokumenten der Sammlung vor, hat er vermutlich keine sinngebende Bedeutung für das Dokument. Vermutlich handelt es sich um ein Stoppwort wie und, der, die, das, auch etc. Kommt ein Term nur in wenigen Dokumenten vor, dann scheint er für das Einzeldokument von größerer Bedeutung zu sein, da sich dieses Dokument durch den seltenen Term von den anderen Dokumenten abhebt.
Auch hier dienen eine Logarithmusfunktion und einige Korrekturwerte dazu Ausreißer im Wertebereich zu unterdrücken.
Was sagen uns die Termgewichte?
Die Gewichtung eines Terms errechnet sich aus dem Produkt von WDF und IDF. Sie gibt an, welche Bedeutung der einzelne Term für das betrachtete Dokument hat. Durch eine hohe Termgewichtung sendet ein Dokument das Signal aus: „Dieser Term ist wichtig für mich“. Betrachtet man die Terme mit den höchsten Gewichtungen in einem Dokument, sollte man einen Eindruck davon bekommen, worum es in dem entsprechenden Dokument geht.
Ein Termgewicht errechnet sich demnach wie folgt:

Nimmt man nun eine Auswahl von Dokumenten, die zu einem bestimmten Suchbegriff gut ranken und betrachtet die Durchschnittswerte der Termgewichte, bekommt man sehr schnell einen Eindruck davon, welche Terme in diesem gut rankenden Dokumenten gemeinhin vorkommen. Der so aufgespannte semantische Raum zeigt, welche Terme neben dem gewählten Suchbegriff noch von Bedeutung sind, bzw. in welchem Kontext der Suchbegriff offensichtlich steht.
Auf die Richtung kommt es an, nicht auf die Dichte
Die Termgewichte bilden die einzelnen skalaren Vektorelemente und legen somit die Richtung des Vektors fest, der ein Dokument repräsentiert. Die Häufigkeit des Auftretens eines Terms in einem Dokument hat demnach nur bedingt Einfluss auf die Richtung des ihn repräsentierenden Vektors. Wichtiger für die Richtung des Vektors sind die Terme die eine starke Gewichtung aufweisen.
So finden sich in einem guten Text zum Thema „Verhütungsalternativen zur Pille“ mit hoher Wahrscheinlichkeit die Terme:
- Schwangerschaft
- Kondom
- Spirale
- Verhütungsring
- Temperaturmethode
- Pearl-Index
Die Analyse zeigt, welche Terme in einem guten Text zu diesem Thema tatsächlich mit welcher Gewichtung verwendet werden und liefert dem Autor – oder auch schon dem Auftraggeber – so einen ersten Einstieg in die Recherche zur Thematik.
Moderne WDF * IDF Analysen in der Suchmaschinenoptimierung
Das Vektor-Space-Modell und die WDF*IDF-Termgewichtungen aus den 70er Jahren bilden immer noch einen zentralen konzeptionellen Kern in aktuellen Suchmaschinen. Bei den damals verwendeten Dokumentkorpussen (alle Dokumente, die die Suchmaschine durchsuchen konnte) handelte es sich um vergleichsweise überschaubaren Sammlungen von mehreren Hundert Texten einer Nachrichtenagentur (z.B. die Reuters-Collection) oder Sammlungen von 2000 Abstracts aus wissenschaftlichen Zeitschriften. Eine Anpassung an die veränderten Rahmenbedingungen, die durch das Internet als einen quasi unendlichen Dokumentkorpus und die Eigenschaften die eine Webseite als Einzeldokument mitbringt, ist daher erforderlich.
In einem HTML-Dokument hat man die Möglichkeit Texte zu strukturieren und Strukturelemente wie eine Überschrift oder Hervorhebungen wie beispielsweise Fettdruck auszuwerten. Dadurch kann man bestimmten Termen eine höhere Gewichtung zuordnen, was mit den Textsammlungen der 70er Jahre nicht möglich war.
Durch die praktisch nicht fassbare Größe des Internets, muss auch der tatsächliche Dokumentkorpus approximiert werden. Gewöhnlich verwendet man hier eine keywordbezogene Auswahl an Webseiten als Dokumentkorpus.
Die IDF-Komponente der Termgewichtung erweist sich bei dieser starken Vereinfachung des Dokumentkorpusses als problematisch. Über die IDF Komponente werden normalerweise Terme in ihrer Gewichtung verringert, die in allen betrachteten Dokumenten vorkommen. Das ist sinnvoll bei Stoppwörtern, jedoch weniger zielführend, wenn es sich bei dem Term um das gesuchte Keyword handelt, dass in jedem der Dokumente vorkommt.
Neben der Positionierung und Auszeichnung der Terme kann auch die Nähe der Terme zueinander im Text von Bedeutung sein. In dem Beispiel von eben dürfte sich mit hoher Wahrscheinlichkeit in der Nähe des Begriffs „Kondom“ eine Formulierung wie „Schutz vor AIDS und anderen Geschlechtskrankheiten“ finden.
Was macht der SEO mit einer WDF * IDF Analyse?
Wozu führt man als SEO eine WDF*IDF Analyse durch? Schließlich handelt es sich um eine ex-post Analyse einer bestehenden Dokumentsammlung. Wie in vielen anderen Bereichen geht es auch hier darum, die Stärken der Mitbewerber zu analysieren und daraus ex-ante Vorgaben für die Konstruktion ebenbürtiger oder sogar besserer Produkte, bzw. Texte abzuleiten. Der SEO nutzt die WDF*IDF Analyse um zu sehen, wie ein gut rankender Text für ein konkretes Keyword aufgebaut ist. Anschließend wird versucht einen möglichst ähnlichen Text zu konstruieren, in der Hoffnung, dass dieser Text ebenso gut oder sogar besser in den Suchergebnissen rankt.
WDF * IDF Analysen bei content.de – von der Analyse direkt zum Auftrag
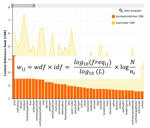
Das content.de Team ist ja bekannt dafür, den Finger immer am Puls der Zeit zu haben und auf die Bedürfnisse des Marktes einzugehen. Daher haben wir für unsere Kunden ein eigenes WDF*IDF-Analysetool entwickelt. Unser WDF*IDF Analysetool berücksichtig verschiedene, rankingrelevante Parameter bei der Bestimmung der Termgewichtungsfaktoren. Für die sinngebenden Terme aller Dokumente aus dem Zielraum der Keywordvorgabe errechnet das content.de System den Content Relevance Rank (CRR) der die SEO-Bedeutung des Terms in dem jeweils betrachteten Dokument angibt.
Für die Analyse werden der durchschnittliche CRR und der jeweils maximale CRR Wert aus den ausgewerteten Daten übersichtlich dargestellt. Unser Tool unterstützt dabei auch die direkte Textbeauftragung auf Basis der durchgeführten Analyse.
Fazit: Bleib authentisch
Eine WDF*IDF – Analyse zeigt zu relevanten Termen, die in den gut rankenden Dokumenten zu einem bestimmten Suchbegriff vorkommen, eine individuelle Termgewichtung und visualisiert so einen semantischen Raum, in dem sich diese Dokumente bewegen. Sie kann als Unterstützung für Recherche im Zuge der Texterstellung dienen und dem Autor grob aufzeigen, wo er Schwerpunkte legen sollte, was zu berücksichtigen ist und auch was offensichtlich weniger von Interesse ist. Grundsätzlich gilt immer noch die goldene Faustformel für einen guten Text: „Schreibe einen fokussierten Text, der alle relevanten Aspekte eines Themas angemessen berücksichtigt und einen individuellen Schwerpunkt setzt.“ Eine WDF*IDF-Analyse kann dabei unterstützen, eine grobe Ausgangsbasis zu finden, sie darf nicht zu einem starren Korsett werden, mit dem ein Klon bestehender Texte erstellt wird.
Der Text ist ein – sicherlich wichtiger – Ranking Faktor. Das finale Ranking bestimmen zahlreiche andere Faktoren weiterhin mit.
Die Ergebnisse einer WDF*IDF-Analyse müssen auch mit Verstand ausgewertet werden, insbesondere, wenn sie die Grundlage für die Erstellung eigener Texte bilden sollen. Mehr dazu erfahren Sie im zweiten Teil unserer Reihe zur WDF*IDF- Analyse.
Pingback: WDF-IDF: Was ist das und wie nützlich ist die Termgewichtung wirklich? - How to WordPress
Gleich mal probieren. Danke euch. Habe bisher immer geschaut, dass ich 2% Keyworddichte erreiche!
Pingback: 5 Tipps für gute Webtexte. | Blog content.de
Pingback: 8 Tipps für eine effektive Vorarbeit durch den Auftraggeber | Blog content.de
Pingback: content.de - Individuellen Content für Webseiten kaufen - Trafficjunkies
Vielen Dank für den sehr informativen Artikel.
Viele Grüße
Sebastian
wieder was gelernt 😉
Aber wenn wir schon dabei sind: Es handelt sich übrigens um “das Korpus”, Plural “die Korpora”, wenn von größeren Textsammlungen die Rede / Schreibe sein soll 😉
… und Terme falsch geschrieben. Ich saß beim Tippen im Keller. 😉
“…allerdings nicht bei Content.de.” Diese Feststellung freut uns. 🙂 Eben weil wir nicht wünschen, dass Autoren in einem Editor tippen und dabei versuchen einen Text so zusammen zu puzzeln, dass eine Linie zwischen zwei Kurven einer Grafik gequetscht wird, läuft es bei uns anders. Wir zeigen den Auftraggebern “das Ergebnis”, also den fertigen Text, nicht in Form einer Grafik an, oder werten den Text nochmals mit einem WDF*IDF Verfahren aus. Denn auch wir wollen vermeiden, dass ein guter Text in Revision geht weil irgendwer der Meinung ist, dass in irgendwelchen Tools irgendwelche Kurven sagen, dass es angeblich kein passender Text ist.
P.S.: Die “Keys” hießen schon früher “Keywords” und ganz früher eben Terme, denn die Therme bleibt im Keller und macht weiterhin das Wasser warm 😉
Fein, fein – die Keys heißen jetzt Therme und einen Zähler gibt es ab sofort nicht mehr.
Was bedeutet das für den Autor? Das wird sich hoffentlich bald herausstellen, wenn auch die Auftraggeber sich mit dem Thema intensiv auseinandergesetzt haben und aus der Bastelphase herausgekommen sind. Bis dahin missbrauchen offensichtlich einige Unwissende den Autor als Versuchskaninchen, um intern fröhlich Diagramme zu vergleichen, indem sie ein Programm (das dem Autor nicht zur Verfügung steht) mit Content füttern. Die Beta-Tester bestaunen mit großen Augen die bei jeder Satzumstellung veränderten Kurven. Dazu muss natürlich ein sorgfältig geschriebener Text mehrfach verändert, angeglichen und gequält werden. Therme (Keys) werden vermehrt hinzugefügt, vermeintlich überflüssige entfernt. Bei der nächsten Änderung ist es genau andersherum, weil sich diametral auch die Therme-Wichtung im WDF-Analyse-Tool verändert. Die Quälerei betrifft nicht nur den Text, sondern vor allem den Autor.
So etwas macht doch niemand? Aber sicher, denn ich habe es genau so in der letzten Woche erlebt – allerdings nicht bei Content.de.
Pingback: Lösen WDF*IDF Analysen die Keyworddichte in der SEO-Analyse ab? » Umsatz im Internet
Pingback: Die Keyworddichte ist tot, es lebe die WDF*IDF-Analyse - sem.de Magazin
Das Tool gibt es bereits 😉
Vielen Dank für die Erklärung auch wenn ich das alles sehr kompliziert finde habe ich den Ansatz denke ich verstanden, wird es bei Content.de ein Tool geben wonach man Texte nach diesem Schema in Auftrag geben kann? Das wäre natürlich sehr interessant 🙂
Muss sagen dass es einer der besten Beiträge zu dem Thema WDF*IDF ist. Viele SEOs schreiben zwar darüber, jedoch ist für den Laien nicht immer alles verständlich. Hier habt Ihr es sehr gut erklärt.
Mit den Bildern und Grafiken ist das ganze dann auch nicht so trocken, top!
Was bislang noch keiner gemacht hat: Einen Beitrag mit und ohne WDF*IDF Optimierung zu schreiben, das wäre ein schönes Beispiel 🙂
Ich habe mich jetzt durch alle drei Beiträge gearbeitet und muss sagen: Hut ab! Da schreibt jemand, der offensichtlich weiß, worum es geht, wunderbar abgeklärt und ohne vor KK auf die Knie zu gehen.
Ich hab ja inzwischen grundsätzlich eine negative Einstellung, wenn sich wieder jemand zum WDF*P*IDF-Hype-Thema äußert. Bei der Lektüre wurde ich eines Besseren belehrt. Hier werden endlich mal sehr deutlich die RICHTIGEN Schlussfolgerungen gezogen: Es geht eben NICHT darum, einen Text zwischen zwei Kurven zu prügeln. Es geht darum einen guten Text zu schreiben. Diese Analysen (ob wir sie nun crr, wdf*p*idf oder eps-kf nennen ist ja egal) sollten nur dazu dienen Ideen für Texte zu bekommen und dafür sorgen, dass wir keine Aspekte vergessen! Daher finde ich auch die Umsetzung zur direkten Textbeauftragung sehr gelungen, die dem Autor eben nicht zwingt bei jedem Tastendruck auf eine Grafik zu glotzen um zu prüfen ob man noch im grünen Bereich ist (so habe ich das jedenfalls verstanden).
Sehr gut gefällt mir auch der Hinweis „Hirn einschalten wenn man ein Tool benutzt“. Ich kenne auch genug meiner Kunden die mit Ausdrucken von irgendwelchen Tools, die sie nicht verstehen, ankommen und sagen: „Hilfe ändere das!“ Danach kommen sie dann mit anderen Tools an, die sie noch weniger verstehen und sagen „Du hast beschissen gearbeitet“. Daher finde ich es wirklich klasse, dass content.de sagt „Hier ist ein neues Tool, aber vergiss das Denken nicht“ und (eigentlich noch viel besser) den Autoren sagt „schreibt einfach einen guten Text, der ist automatisch schon wdf*idf-optimiert und wenn Ihr meint, der Auftraggeber hat keine Ahnung, dann schreibt einfach nicht für ihn!“ Respekt für so eine ehrliche Aussage, die die einzig richtige ist! Weiter so!
Unser kleiner Blog ist zwar noch neu und hat bisher nur ungefähr 2.500 Leser im Monat, aber ich sehe an meiner Statistik auch, wer uns außer unserem Stammlesern, die überwiegend über Facebook, Jappy sowie unser Reiter- und und BGE-Hartz-IV-Forum kommen, wer uns ansonsten über welche Suchbegriffe findet.
Es sind meistens Wortkombinationen, worüber die Leute bei uns landen, oft zwar im Zusammenhang mit Pferden oder sozialkritischen und politischen Themen oder anderen Haustieren, aber einfach über das Suchwort Pferd, Hund oder Hartz IV landen die nie bei uns.
Sie sind in der letzten Zeit, nur um einmal Beispiele zu nennen, über Shanty Pop aus Holstein bei einem Beitrag über Santiano gelandet, die ja einen Echo gewonnen haben .. sie sind über Vorband von The Gossip bei unserem Bericht über deren Konzert gelandet, wo ich die Band genannt habe, sie sind über “Reiterhof Gläserkoppel” bei einem Bericht über eine Reitershow dort gelandet .. sie landen über Hufbearbeitung bei Hufrehe oder Vitamin K3 für Pferde oder Eintopf mit Kohlrabi auf meiner Seite, nie über Pferde, Rezepte, ARGE oder derlei Suchbegriffen, was ich jeden Tag sehe, wenn ich meine Statistik anschaue.
Ach ja .. wir haben einen stinknormalen Google-Blog, der laut Aussagen von SEO-Leuten ja nicht gut sein soll.
Ich habe mir, da ich schon seit über 10 Jahren ein Reiterforum habe, noch nie Gedanken über Keywords gemacht, sondern habe einfach eins bemerkt: Wenn ich nicht viel schreibe, dann sackt mein Forum sofort ab .. es kommt aber wieder hoch, sobald ich auch nur übers Wetter schreibe und mir meine Mitglieder ab und zu antworten, selbst wenn es nicht um themenrelevante Dinge wie ein an Hufrehe erkranktes Pferd geht.
LG
Renate
Diese Erläuterung bringt es auf den Punkt. Ich hab die Diskussion um WDF*IDF im Netz von Anfang an verfolgt und es spricht für die Qualität von content.de, dass es diese Thematik gleich aufgreift.
Als Autor macht die neue Denkweise auch mehr Spaß. Denn so werden die Texte inhaltlich besser und stilistisch braucht man sich nicht mehr so verbiegen.
Pingback: wdi*idf-SEO-Texte Schreiben - so wir's gemacht | Blog content.de
Pingback: SEO-Texte auf Basis einer WDF*IDF Analyse beauftragen | Blog content.de